Flink StreamingFileSink源码分析
Flink StreamingFileSink源码分析
介绍
org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
Flink中的StreamingFileSink是用来将流式数据写入文件系统的Sink。在StreamingFileSink中会将数据首先发送到bucket中,bucket与存储目录相关,然后与Checkpoint机制配合来达到精准一次的语义。
其中BucketAssigner用来定义如何将元素写入哪些目录中,默认的BucketAssigner实现是DataTimeBucketAssigner,每个小时会创建一个bucket。
在写入文件时,文件有三种状态:in-progress,pending,finished,这是为了提供对精准一次语义的保证,新来的数据会首先写入到in-progress文件中,当通过用户定义的RollingPolicy触发了文件的关闭条件时(比如文件大小),会关闭in-progress文件,并向一个新的in-progress文件中继续写数据。直到收到Checkpoint成功的信息时,会将pending的文件转换为finished。

源码分析(Base Flink-1.12.3)
StreamingFileSink工作流程
实例创建
首先分析StreamingFileSink整体工作流程,下文摘录主要源码进行说明。
StreamingFileSink继承自RichSinkFunction,并且实现了与checkpoint相关的两个接口(与Checkpoint有关的功能在下面逐步提及)。
构造函数源码:
1 | public class StreamingFileSink<IN> extends RichSinkFunction<IN> implements CheckpointedFunction, CheckpointListener{ |
StreamingFileSink的构造函数的访问修饰符是protected,需要通过两个Builder方法新建实例。
而且这两个Builder均继承自StreamingFileSink的内部抽象类BucketsBuilder。
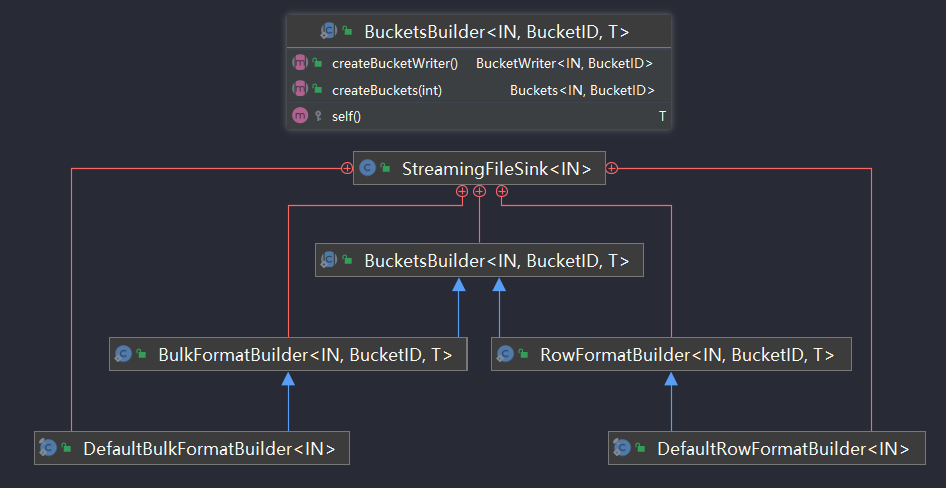
这两个类的实例化是通过StreamingFileSink中的两个静态方法
1 | /** |
状态初始化与数据消费
状态初始化时会创建StreamingFileSinkHelper,这个StreamingFileSinkHelper基本上包含了所有的状态、数据消费的行为。
1 | // StreamingFileSink中实现的与sink以及checkpoint相关的methods |
数据消费的时序图及其说明如下:
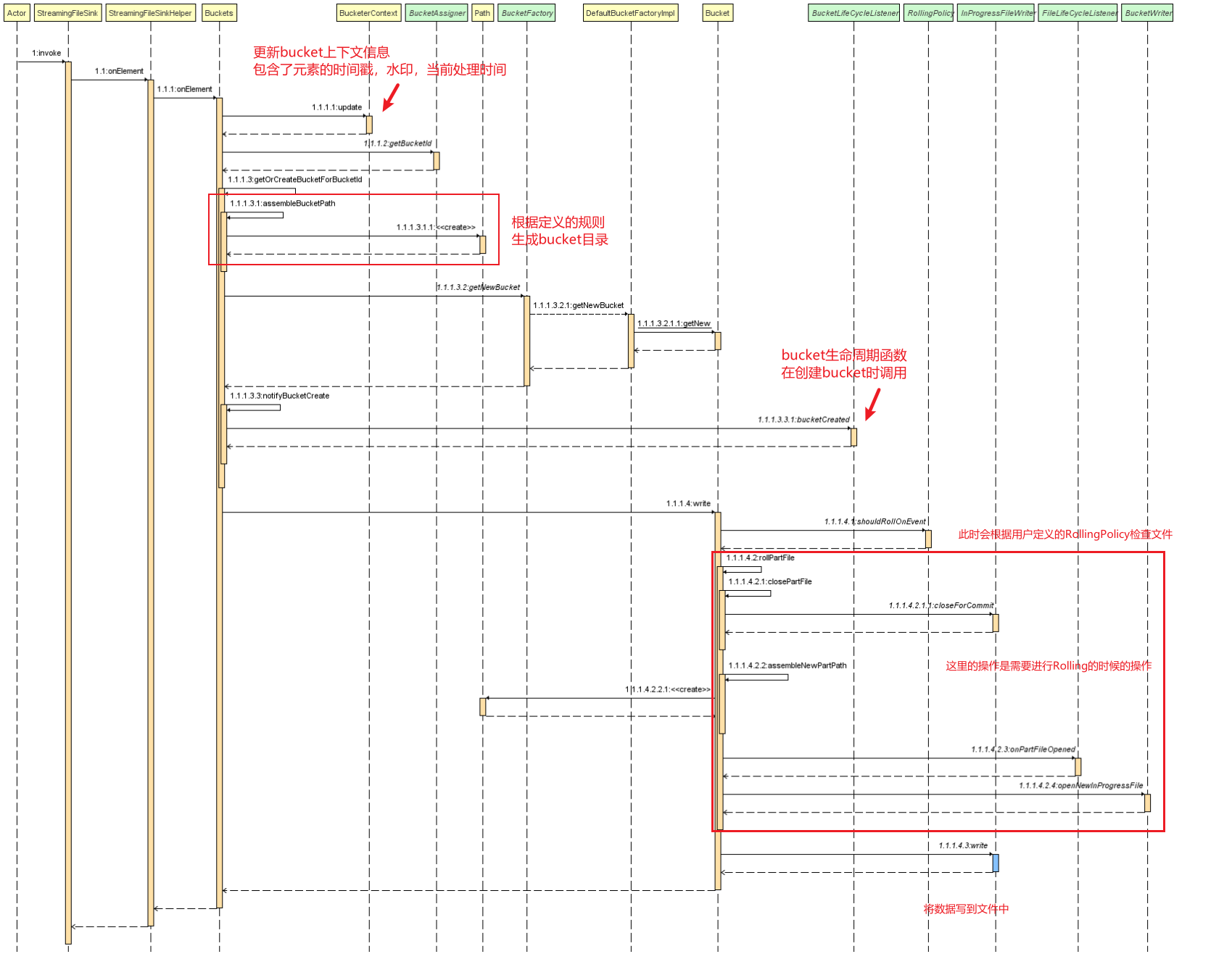
进行数据消费时,主要的步骤有以下几步:
会调用
buckets的onElement方法来进行写数据之前的一些状态更新和bucket的检查,检查bucket所对应的目录,这部分的代码主要是org.apache.flink.streaming.api.functions.sink.filesystem.Buckets#getOrCreateBucketForBucketId1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20private Bucket<IN, BucketID> getOrCreateBucketForBucketId(final BucketID bucketId)
throws IOException {
Bucket<IN, BucketID> bucket = activeBuckets.get(bucketId); // 根据bucketid检查一下之前是否创建过bucket
if (bucket == null) { // 创建一个新的bucket
final Path bucketPath = assembleBucketPath(bucketId);
bucket =
bucketFactory.getNewBucket(
subtaskIndex,
bucketId,
bucketPath,
maxPartCounter,
bucketWriter,
rollingPolicy,
fileLifeCycleListener,
outputFileConfig);
activeBuckets.put(bucketId, bucket);
notifyBucketCreate(bucket);
}
return bucket;
}bucket检查完成后调用bucket的write方法,即org.apache.flink.streaming.api.functions.sink.filesystem.Bucket#write,在write方法中会检查文件是否触发了rolling的条件,如果触发了rolling则关闭当前文件,再新建下一个文件;然后将数据写入文件中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15void write(IN element, long currentTime) throws IOException {
if (inProgressPart == null || rollingPolicy.shouldRollOnEvent(inProgressPart, element)) {// 检查是否触发了需要rolling的条件
if (LOG.isDebugEnabled()) {
LOG.debug(
"Subtask {} closing in-progress part file for bucket id={} due to element {}.",
subtaskIndex,
bucketId,
element);
}
inProgressPart = rollPartFile(currentTime);
}
inProgressPart.write(element, currentTime); // 向in-progress文件中写数据
}在
org.apache.flink.streaming.api.functions.sink.filesystem.Bucket#rollPartFile方法中,执行的org.apache.flink.streaming.api.functions.sink.filesystem.Bucket#closePartFile方法,会将当前关闭的in-progress文件存入状态中,等待checkpoint时使用。1
2
3
4
5
6
7
8
9
10private InProgressFileWriter.PendingFileRecoverable closePartFile() throws IOException {
InProgressFileWriter.PendingFileRecoverable pendingFileRecoverable = null;
if (inProgressPart != null) {
pendingFileRecoverable = inProgressPart.closeForCommit();
// 将文件关闭。处于当前checkpointid时,该状态会保存所有关闭的in-progress文件,实际上此时文件逻辑状态已经转换为pending。
pendingFileRecoverablesForCurrentCheckpoint.add(pendingFileRecoverable);
inProgressPart = null;
}
return pendingFileRecoverable;
}
文件状态转换与checkpoint
在触发checkpoint时有两个方法,一个是常规触发checkpoint时执行的snapshotState方法,另一个是checkpoint完成时执行的回调notifyCheckpointComplete
因为在写文件时需要一致性的保证,所以采用这种两阶段提交的方式,在执行notifyCheckpointComplete方法后才会真正的提交完成。
执行checkpoint逻辑
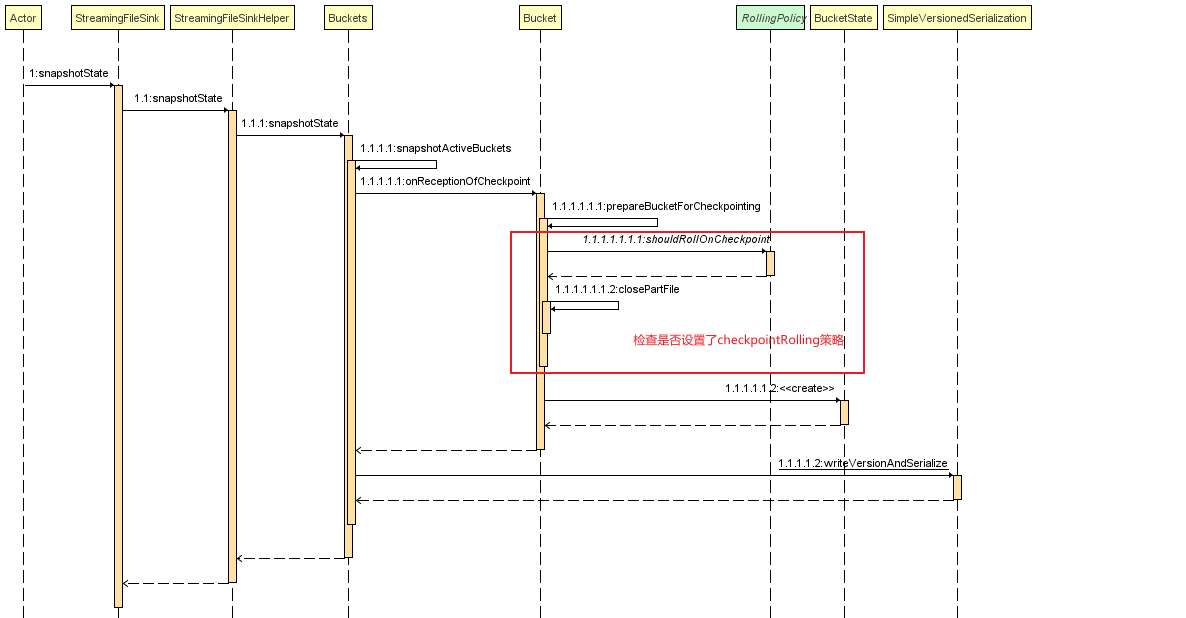
在org.apache.flink.streaming.api.functions.sink.filesystem.Buckets#snapshotActiveBuckets中依次对每个bucket调用org.apache.flink.streaming.api.functions.sink.filesystem.Bucket#onReceptionOfCheckpoint,然后再将onReceptionOfCheckpoint返回的状态进行序列化保存
这其中的主要方法是onReceptionOfCheckpoint,这是每个bucket执行checkpoint的主要逻辑.
在这个方法中可以主要分为两个部分,其一是处理pending状态的文件,其二是处理当前正在写的in-progress文件
1 | BucketState<BucketID> onReceptionOfCheckpoint(long checkpointId) throws IOException { |
- 处理pending文件的状态主要是以下方法
1 | private void prepareBucketForCheckpointing(long checkpointId) throws IOException { |
处理当前正在写的in-progress文件的状态主要是这个代码段
1
2
3
4
5
6
7
8
9
10
11
12BucketState<BucketID> onReceptionOfCheckpoint(long checkpointId) throws IOException {
...
// 如果当前正在写的文件不为空,需要处理当前正在写的文件,记录相关信息到状态中
if (inProgressPart != null) {
// persist()主要是用来保存当前状态写入的信息,比如写入偏移量,
inProgressFileRecoverable = inProgressPart.persist();
inProgressFileCreationTime = inProgressPart.getCreationTime();
this.inProgressFileRecoverablesPerCheckpoint.put(
checkpointId, inProgressFileRecoverable);
}
...
}
checkpoint完成时
org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink#notifyCheckpointComplete方法用来执行checkpoint完成时的逻辑
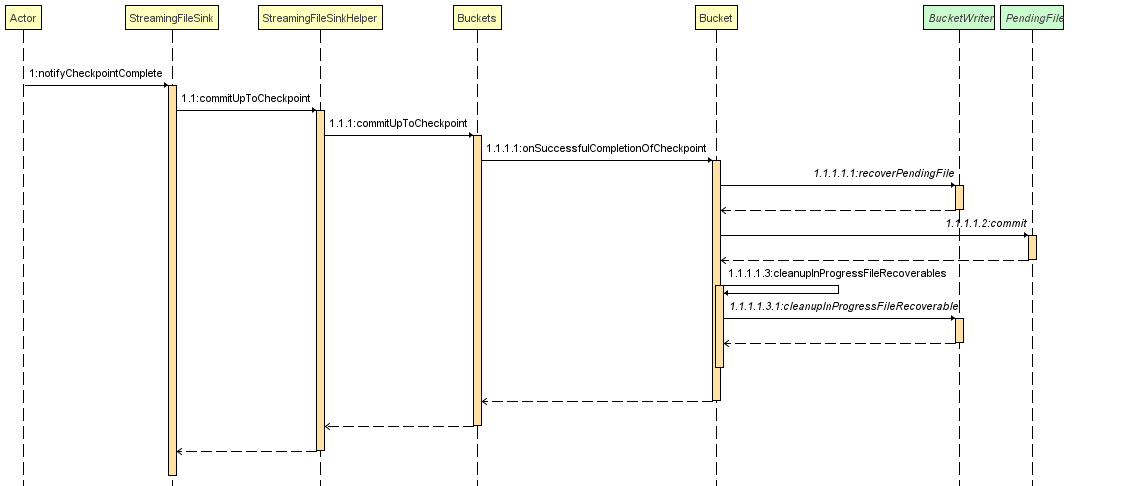
这其中最终调用的方法是org.apache.flink.streaming.api.functions.sink.filesystem.Bucket#onSuccessfulCompletionOfCheckpoint
1 | void onSuccessfulCompletionOfCheckpoint(long checkpointId) throws IOException { |
至此,StreamingFileSink对数据的处理流程基本完成。
附:
写数据时的inprogress文件

finished文件,可供下游使用

StreamingFileSink对Failover的处理
StreamingFileSink在恢复状态时,会恢复每个bucket中的计数信息、正在写的in-progress、pending的信息。
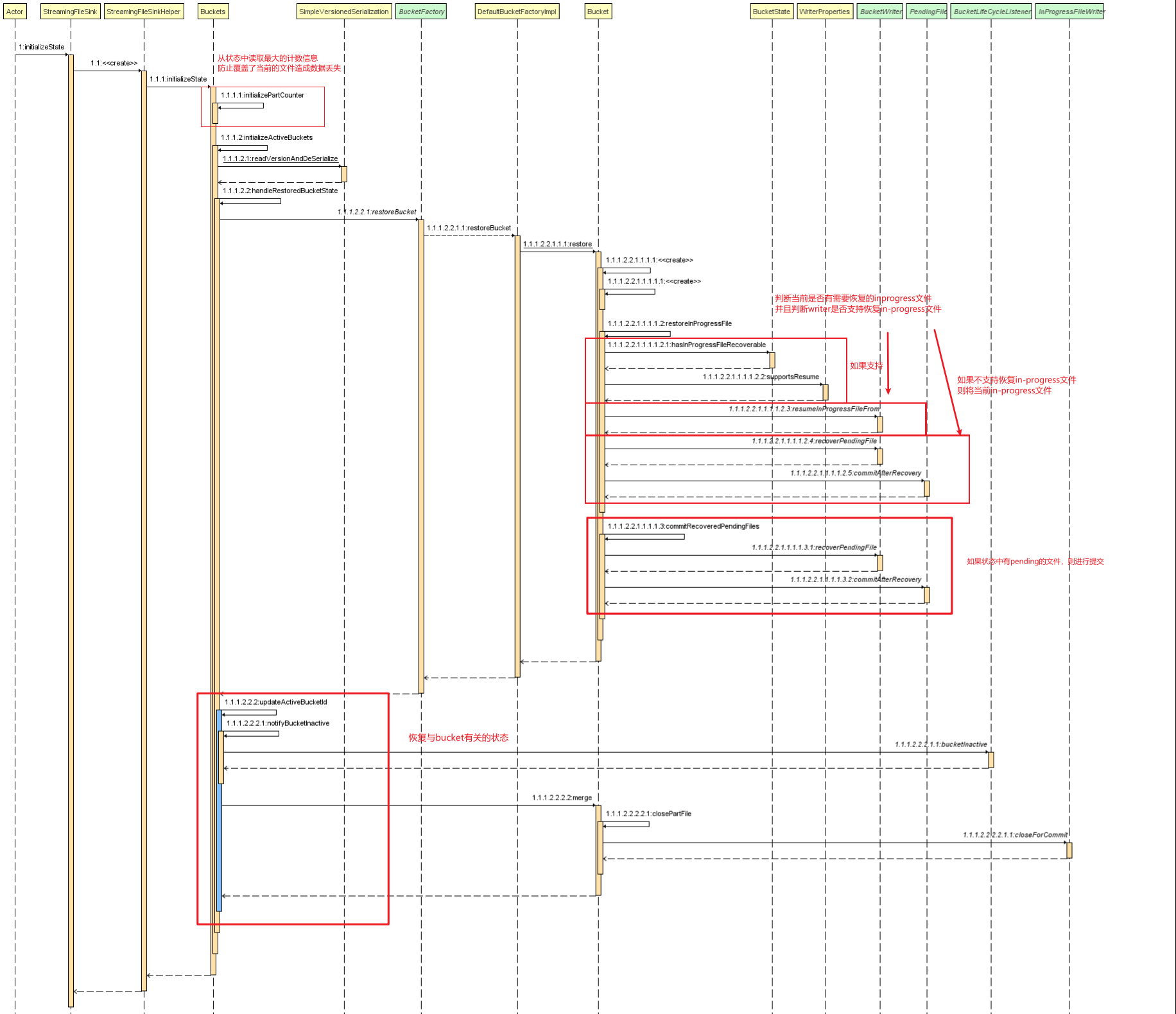
当Failover出现在不同的阶段: