
ClickHouse分布式表介绍
ClickHouse分布式表介绍
ClickHouse中的分布式表,本身并不存储数据,而是要依赖一些本地表
在进行分布式表创建时其实是指定的创建表的引擎为Distributed
1 | CREATE TABLE IF NOT EXISTS events ON CLUSTER test_cluster |
Distributed引擎需要以下几个参数:
- 集群标识符
注意不是复制表宏中的标识符,而是中指定的那个。 - 本地表所在的数据库名称
- 本地表名称
- (可选的)分片键(sharding key)
该键与config.xml中配置的分片权重(weight)一同决定写入分布式表时的路由,即数据最终落到哪个物理表上。它可以是表中一列的原始数据,也可以是函数调用的结果,如上面的SQL语句采用了随机值rand()。注意该键要尽量保证数据均匀分布,另外一个常用的操作是采用区分度较高的列的哈希值。
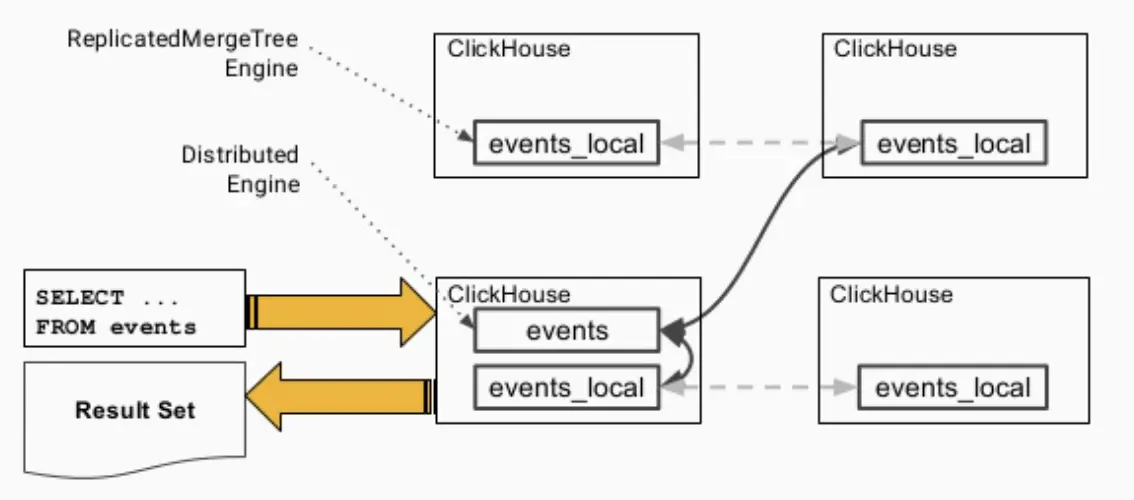
在分布式表上执行查询的流程简图如下所示。发出查询后,各个实例之间会交换自己持有的分片的表数据,最终汇总到同一个实例上返回给用户。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 CCCCCoke!

评论
